I hope some of you find this useful; I have been researching purchasing a new modeling server, and the results should be interesting to those trying to optimize the performance on their own machines, or are thinking of purchasing new machines. There are a number of new architectures that have interesting properties to consider when trying to optimize the performance of ROMS. To understand some of the conclusions and results I present below, it is useful to read Sacha's post: viewtopic.php?f=17&t=2001&p=7771#p7714 . Not all of these results are new, but it is worth pointing out that they are still valid on new architectures.
Summary of results:
- On modern architectures like AMD's Epyc and Intel's Scalable Xeon with non-uniform memory access (NUMA), MPI performs much better than openMP when running with many threads or processes.
- ROMS scales well with increasing number of MPI processes (eg. NtileI*NtileJ) until the number of processes exceeds twice or three times the number of memory channels -- two to three processes per memory channel is about as good as it gets.
- The new AMD architectures are very competitive and at the high end give the best performance among the systems I tested.
Three systems were tested. A Ryzen 1800x that I own; the memory is clocked at 3200Mhz, the CPU at 3.6Ghz, and there are 8 cores and two memory channels. Silicon Mechanics allowed me to benchmark three systems. The first was a dual CPU Epyc 7601 with 2600Mz memory, the CPU at 2.2Ghz, and 64 cores and 16 memory channels. The second was a single CPU Epyc 7601 with 2600Mz memory, the CPU at 2.2Ghz, and 32 cores and 8 memory channels. The third was a dual Xeon Gold 6138 with 2600Mhz memory, the CPU at 2Ghz, 40 cores and 12 memory channels. In all systems, all memory channels are populated by a single stick of RAM.
The Epyc and Xeon systems have non-uniform memory access (NUMA); this means that each core can only access some of the memory at the highest speed, and access to the rest of the memory is at a significant speed and latency penalty. When ROMS is run in parallel using openMP it seems to resided as a single region of memory. So when run with many threads on many cores, many of the cores have to access the ROMS arrays at locations where the memory bandwidth from that core is slow. However, when ROMS is parallelized with MPI, the code is broken up into 1 process per thread (and also one process per tile). Linux will automatically move the process in memory to memory that is most rapidly accessed by that process (google numastat to see how to monitor this). Because of this, memory access will be faster for codes run with MPI when running on a large number of cores. This is clearly seen in the graph below, which shows how quickly the model runs as a function of the number of processes or threads used for both MPI (solid lines) and openMP (dashed lines) for the Epyc and Xeon systems. This hypothesis was confirmed by using numastat to monitor memory latency while running the model. The circles indicate when the number of threads or processes equals the number of memory channels for the system.
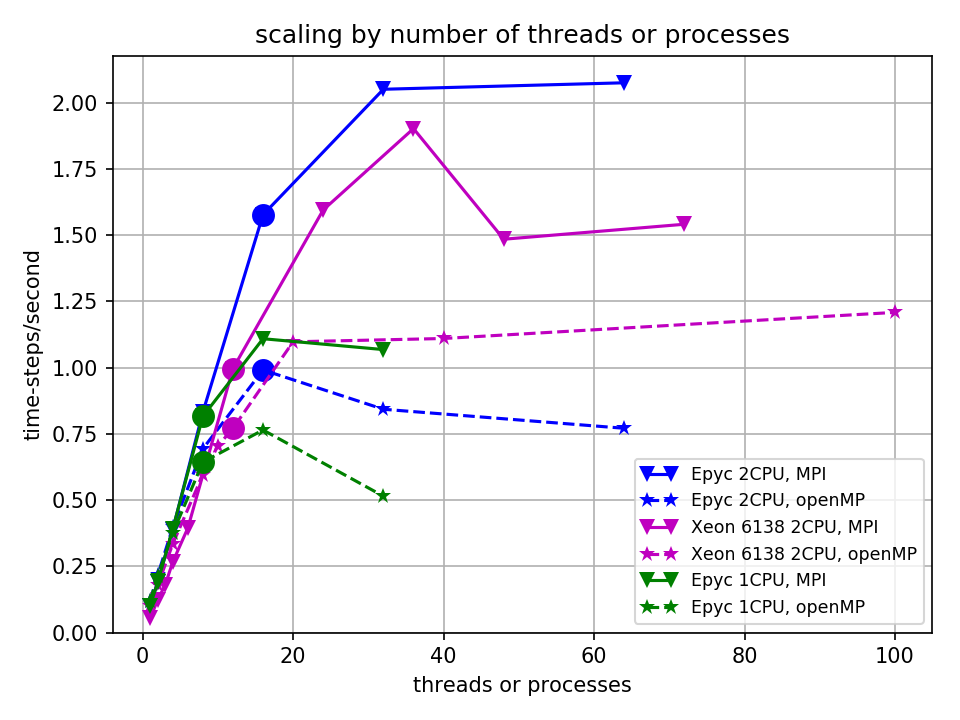
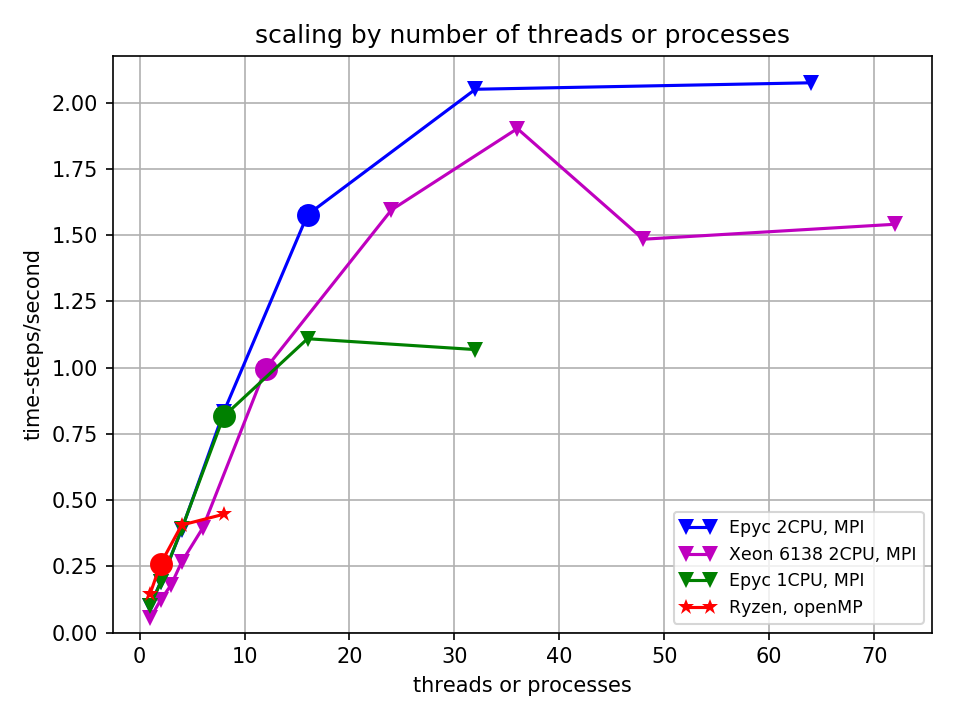
In the following figure, the speed of the model runs in time-steps/second is shown as a function of thread or process count for each of the systems, each configured in the optimal manner w.r.t. openMP/MPI and tiling. At low thread counts, the high-clock speed Ryzen wins. But as the numbers of threads increases, systems with more cores run faster, as we would expect. However, note the circles on the plots -- these mark where the number of MPI processes or openMP threads matches the number of memory channels. It is clear from this figure that the increase in performance with number of processes plateaus at 2 to 3 times the number of threads/processes as memory channels.
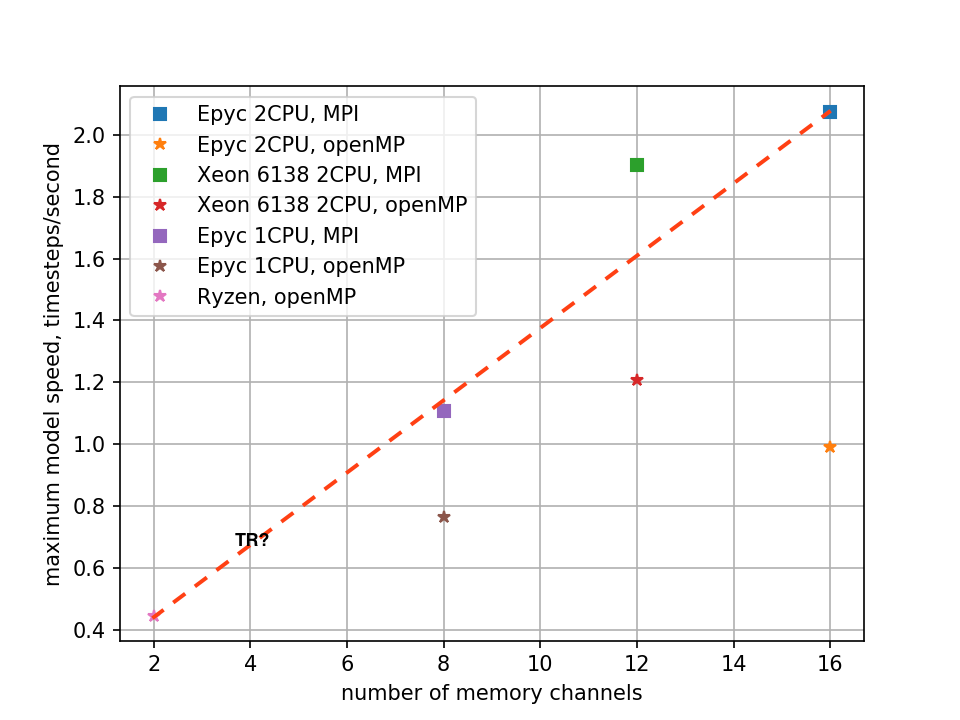
To hammer this point home, below is a figure showing the maximum model speed as a function of number of memory channels. Squares are with MPI, stars with openMP. When running with the more efficient MPI on the Epyc and Xeon systems, it can be seen that the maximum performance scales as roughly linearly with number of memory channels. The Xeon is a bit of outlier in the last two plots -- it is unclear to me if this is because the ratio of (CPU clock speed) to (Memory speed) is lower, or because its memory system has lower latency. Nonetheless, the 2 CPU Epyc system ends up out performing it, consistent with its increased number of memory channels.
Finally, a few thoughts on performance/price of these systems. I hesitate to put this in here. If you are reading this much after the Fall of 2017, realize the world has likely moved on... the principles will likely remain valid, but the details will have shifted. Also, PLEASE NOTE WELL: this discussion is about the performance/price of using these machines to run ROMS. For doing, for instance, data analysis with Python and Matlab, one should likely pay more attention to the performance of a single thread (e.g. Intel i7s, Ryzens, Threadrippers, etc). These have much higher clock speeds, and so per core performance that can be twice as fast as the big server chips. Also, note that I am GUESSING at the performance of an AMD Threadripper chip based on the number of memory channels it has. I have not used one. My estimate is conservative, given that a Threadripper has the high clock speed and memory speed of the Ryzen chips.
If I configure a basic system for each of these, with just the CPU(s) and a 1Tb SSD boot disk (and a cheap graphics card if needed). I assume I need no more than 3 cores per memory channel. All memory channels are filled with 8Gb each, with the fastest supported. I estimated prices from various vendors on the internet -- this is approximate! Also, I chose the Xeon 6140 since it has slightly fewer cores and slightly faster per core clock, and so I am slightly guessing as to its speed...
- Ryzen 1800x 8 cores: 1360$ for 2 memory channels, 0.44 timesteps/second in benchmark3
- Threadripper 1920x 12cores: 2220$ for 4 memory channels, 0.7 timesteps/second
- Dual Epyc 7351 2*16 Cores: 7800$ for 16 memory channels, 2.1 timesteps/second
- Dual Xeon Gold 6140 2*18 cores: 9250$ for 12 memory channels, 1.9 timesteps/second
- Ryzen 1800x 8 cores: 3090
- Threadripper 1920x 12cores: 3170
- Dual Epyc 7351 2*16 Cores: 3710
- Dual Xeon Gold 6140 2*18 cores: 4868
Comments/corrections welcome.
Jamie